Improve ML model performance using Tensorflow Serving
Nov 15, 2021One of the key factors of bring Machine Learning into real world applications/products is to be able to serve machine learning (ML) models as a production service efficiently. Large size ML models, which have more and more frequently become the norm, makes this task even more difficult. In this article, we will take a look at how you can improve ML service performance and throughput with large ML models by using a high-performance serving system - Tensorflow Serving.
Scale MaaS costs the big bucks
ML models as a service (MaaS) enables ML predictions to be plugged into a typical web application service chain as a backend service, and therefore consumed by another web service or even directly by frontend application via API calls. However, just wrapping ML models into a web server and outputting the exciting inference results are not enough. To satisfy real world traffic, ML service has to be able to scale, supporting hundreds or even thousands of requests per second (RPS). If a single ML service instance supports very low RPS, then a large number of ML serving instances would be required to meet the production traffic. This will significantly increase the cost of MaaS in production, and sometimes (if not often) becomes a huge blocker for businesses to adopt machine learning technologies to develop innovative products.
Let's crunch some numbers. Imagine our ML models are 10GB in total, and we want to serve the models in a GPU instance for accelerated computing and better latency. One of the common EC2 instance that AWS offers for ML inference is p3.2xlarge, which costs $3.06/hour on demand, and gives us 1 GPU with 16GB memory. It also has 8 CPUs and 61GB CPU memory for any non-GPU computing related tasks from web server workers or data transfers. Since our ML models fit into 16GB GPU memory, we can preload the ML models into memory to improve real-time inference latency. With all those factors taken into account, let's say a single client request to our ML service takes 500ms to finish from start to finish. This puts our throughput at 2 RPS (requests per instance).
Now, imagine in real world we need to support a customer traffic of 100 RPS, then our monthly cost would be 100/2 (instances) * $3.06 (per hour) * 24 (hour) * 30 (days) = $110, 160. That's more than 100K per month! You can of course get cheaper cost by using CPU instance, but a lot of data and computing intensive ML service requires GPU to achieve better or acceptable latency for production customers. Monthly cost of 100K just for production instances can of course be absorbed by well funded businesses, but it puts a significant dent on the budget for small businesses or startups.
ML service scaling has a memory problem
Believe it or not, that's what we had to deal with when we first built our ML service. Moreover, our real use case is even worse, because we have to use a more expensive EC2 instance due to much bigger ML models (nearly 40GB in total) we have to serve. We therefore embarked on a journey to find solutions to improve the performance and throughput of our ML service. In the below sections, we will look at how we use Tensorflow Serving as the serving system for our ML service, and improves our service throughput from 2 RPS to a significant boost of 12 RPS (requests per second).
Before we dive in, here is a quick description about our requirements. Our total ML models size is 40GB. We use AWS GPU instance for serving to achieve lower inference latency. The instance type we use is g4dn.12xlarge which is a multi-gpu instance with 64GB GPU memory and can contain our total ML models.
Typical ML service architecture
When we first started, we serve our models using a typical ML service architecture shown in the below diagram. We have Nginx as the proxy web server, Gunicorn as the WSGI (Web Server Gateway Interface), Flask as the web framework, and Tensorflow as the ML inference framework. In runtime, a user request comes through to the Flask server, and the server calls a python code/function to run inference on Tensorflow models to produce predictions.
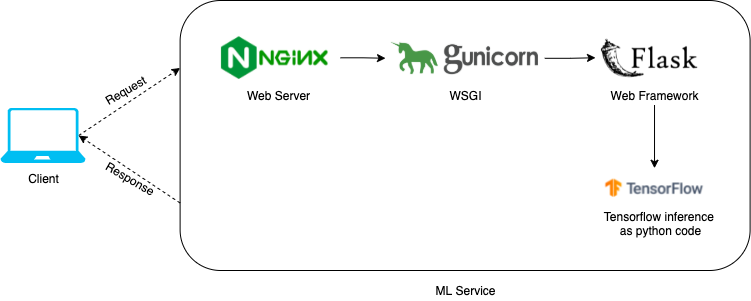
Figure 1: Typical ML service architecture with Tensorflow
Memory limitation prevents scaling
What's the issue then, you might ask? Well, this architecture works fine for small ML models. For scaling, we just need to increase the number of Gunicorn web workers, and it should be able handle more concurrent requests and therefore achieve a better throughput. In this architecture, adding an additional Gunicorn web worker means loading another copy of ML models into memory. It won't be an issue if our ML models are small enough, say, 1GB.
However, this won't be true for bigger ML models. A serving instance has limited CPU/GPU memory, therefore the bigger the ML models, the fewer web workers we can use. The need of using GPU instance makes the case worse. CPU memory is cheaper than GPU memory and you can easily find an instance with large enough CPU memory without breaking the bank. But the price of GPU instance and the limited GPU memory you can get pose an expensive limitation on big ML models. For example, a typical GPU instance that AWS offers for serving such as g4dn.12xlarge has 64GB GPU memory in total and costs $3.912/hour. It's more than enough to achieve a desired scaling by spinning up 10-20 web workers with only 1GB ML model. However, for a 40 GB ML model, we can barely spin up 2 web workers and the throughput is severely limited.
To illustrate further, below is a diagram that looks at the typical ML service architecture from the perspective of memory usage. As you can see, 1 Gunicorn web worker is the best we can do due to memory limitation. Adding another web worker would mean loading another copy of 40GB ML models, which will overflow the instance memory. With a typical ML serving architecture, serving big ML models limits the number of web workers we can use, and therefore limits the service throughput we can achieve.
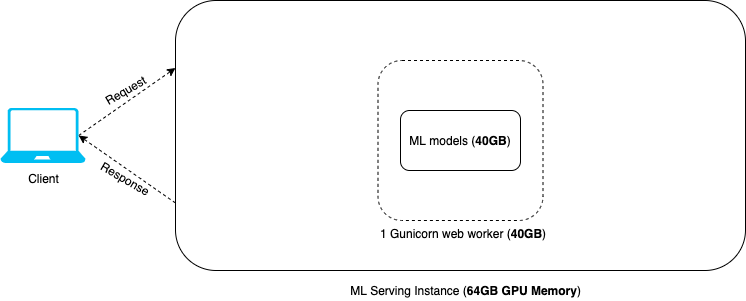
Figure 2: Memory usage in typical ML serving architecture
Scale ML service with Tensorflow Serving
The problem with the above ML service architecture is the coupling of web workers and ML models. On the upside, it makes that running ML predictions is as easy as calling a python function inside Flask server to run a Tensorflow session. On the downside, it makes it impossible to scale up web workers without loading more copies of ML models into memory.
ML service architecture with Tensorflow Serving
Tensorflow Serving, developed by Tensorflow team, is a high-performance serving system for serving machine learning models. Here are some great features Tensorflow Serving offers:
- Serve multiple ML models in a single REST API or gRPC API
- Out-of-box model versioning management (A/B testing of ML models)
- Request batching for finer model inference performance tuning
- Adds minimal latency to inference time due to efficient, low-overhead implementation
Of all the features it offers above, the best one is perhaps that it serves ML models in a separate Tensorflow serving server and expose a single REST/gRPC API, therefore successfully decouples ML models from web server. As you can see in the diagram below, a user request comes to the web server first, instead of running ML inference directly in the web server, it sends an API inference request to Tensorflow serving server, where it runs the ML inference is run and then returns the ML predictions back to web server.

Figure 3: ML service architecture with Tensorflow Serving
Tensorflow Serving removes memory limitation
Tensorflow Serving, by decoupling ML models from web server, removes memory limitation suffered by typical ML service architecture and effectively allows web workers to scale. In this service architecture, increasing the number of web workers in the web server won't require loading extra copies of ML models in each web worker. Instead, we only have to load 1 copy of ML models into memory, and Tensorflow Serving server serves the ML models as a single API endpoint. Having the ability to use multiple web workers to receive requests from the client, we effectively improve the throughput of the ML service.
Take our use case for example, as shown in the diagram below. By adopting Tensorflow Serving to server our ML models, we were able to scale our web workers from 1 to 12, which improves our instance RPS from 2 to 12, after thorough load testing. The serving instance we use would of course have a bigger GPU memory than the total size of our ML models, allowing us to load 1 copy of ML models, and also use multiple Gunicorn workers.
Why not using more Gunicorn workers than just 12 if it improves the throughput so much, you might ask? Well, as similar with a typical web server, this ML service architecture also requires fine tuning and adjustment to specific use cases to achieve best performance and also satisfy potential constraints. In the section below, we will take a look at some fine tuning approaches and constraints.
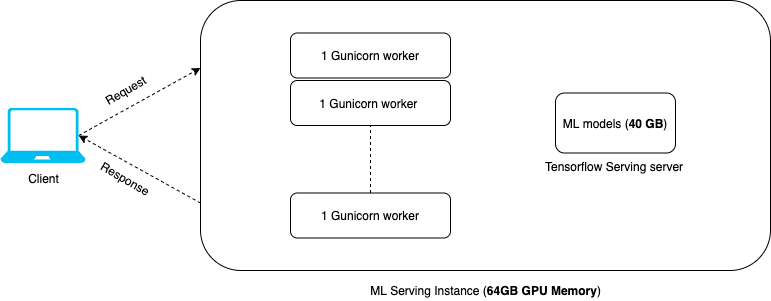
Figure 4: Memory usage in ML service architecture with Tensorflow Serving
Performance fine tuning
First, fine tune the number of web workers for your ML service. The number of web workers we can use are still constrained, mostly due to memory need for the pre-processing and post-processing steps you may run before/after ML inference. In a common ML service, you may need to run pre-processing step on the data you receive from client request to prepare it for inference, and you may need to run post-processing step on the inference result to optimize or reformat it before sending the response back to client. The pre-processing or post-processing step needs to be handled in the web worker, not Tensorflow Serving server. If either pre-processing or post-processing step requires any tensors, parameters, or small models to be loaded into memory when the server starts for runtime performance, then each web worker would consumer some amount of GPU memory. That will constrain the number of web workers we can scale up due to instance memory limitation. Fine tuning is needed for your ML service to find out the optimal number of web workers you can use without overflowing instance memory. Besides that, allow memory room for runtime operations as well.
Second, fine tune Tensorflow serving server with request batching. You may have noticed that even if we have multiple web workers to handle client requests, our Tensorflow serving server is still a single-worker server. If ML inference take up the majority of your ML service latency, it could become a bottleneck because inference requests from web works to Tensorflow serving server will start piling up in high traffic load time. To improve this limitation, Tensorflow Serving offers server-side request batching feature out of box, as described more in details in its official documentation. Request batching enables Tensorflow serving server to wait with a certain timeout until it accumulated a specific number of requests, and then run inference in batch for all requests. This feature can significantly increase the throughput of Tensorflow serving server, with some compromise on inference latency. Fine tuning is needed to find the optimal timeout and batch size that work best for your ML service.
Third, fine tune the web worker type for your ML service. The type of WSGI server worker, in our case Gunicorn worker, affects the performance of ML service as well. Typical Gunicorn worker types such as sync worker, async worker (Gevent), or AsyncIO worker(gthread) work differently from each other. Choosing the right web worker type can significantly impact the performance of your ML service based on the characteristics of the service. For example, if your ML service is compute-bound, which is often due to expensive runtime computation, then sync worker is a better worker type to use. On the contrary, if your ML service is I/O-bound, which is often due to doing a lot of filesystem read/write or network requests, then async worker or asyncIO worker works better. To find out what works out the best, it's important to fine tune the web worker type you use and do load testing on your service.
Final Words
In this article, demonstrated with our use case, we looked at how memory limitation becomes the bottleneck to scale ML service with large size ML models, and how Tensorflow Serving can change the ML service architecture to remove the memory limitation and allow ML service to scale. With the adoption of deep learning training, large size ML models are here to stay and get even larger. With that, scaling ML service in production with large size ML models is a costly business, especially with more and more demanding traffic that a business/application have to satisfy. If you are in a similar boat to scale your ML service, consider giving Tensorflow Serving a try.